闲来无事做了一个打牌记账的工具,因为之前用过其他人的,感觉不是很好用,而且广告很多,自己就做了个,目前代码就不开放了(等以后功能稳定后,就开放仓库),可以扫码体验,以后打牌记账可以用我的这个,里面用到了socket,有bug可以通过小程序里 – 帮助 – 向作者留言 反馈

界面预览:(简洁无广告)
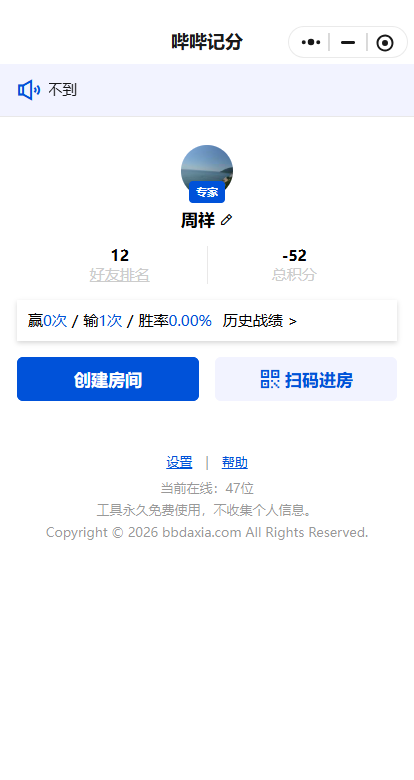
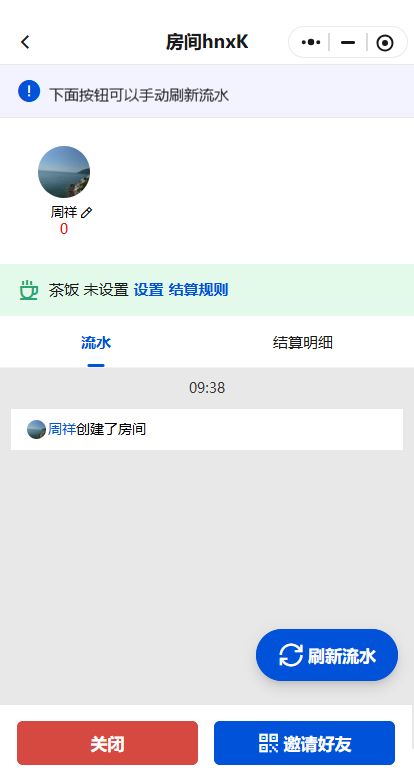
闲来无事做了一个打牌记账的工具,因为之前用过其他人的,感觉不是很好用,而且广告很多,自己就做了个,目前代码就不开放了(等以后功能稳定后,就开放仓库),可以扫码体验,以后打牌记账可以用我的这个,里面用到了socket,有bug可以通过小程序里 – 帮助 – 向作者留言 反馈
界面预览:(简洁无广告)
(后续就不更新了)
演示网址: https://www.bbdaxia.com/shenpiDemo (未做兼容,请使用谷歌浏览器(webkit内核)访问,点击顶部4个tab导航可以切换)
源码下载:https://gitee.com/netzhouxiang/dingding
本次讲解如何实现流程设计和相关代码释义,先看最终效果:
整体效果:
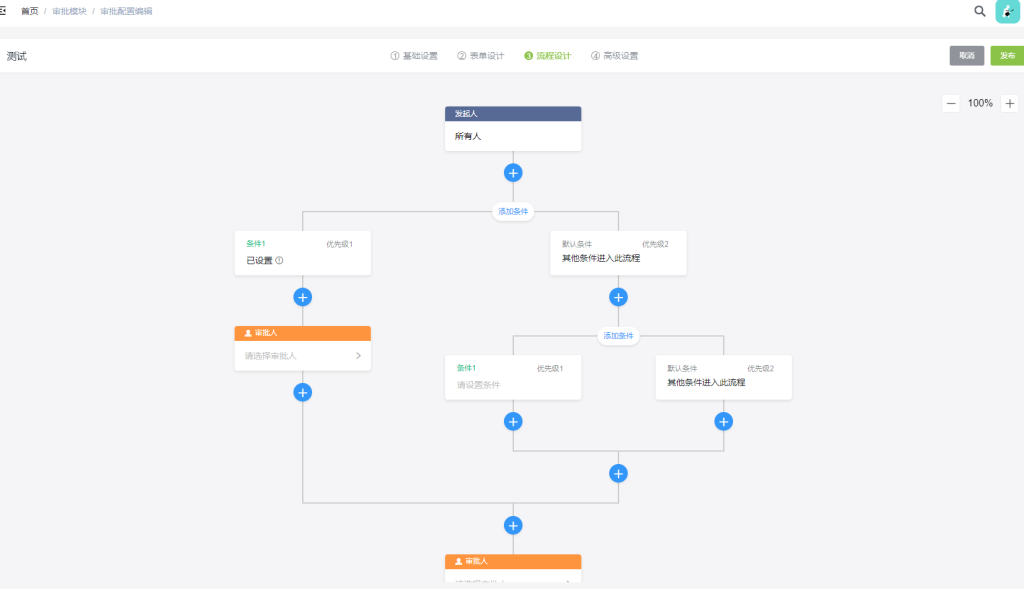
这个也是工作中已经实现过了,拿出来讲解一下,因为是公司项目,所以项目源代码就不分享了,现在看一下实现过程和echarts各配置
正式效果:
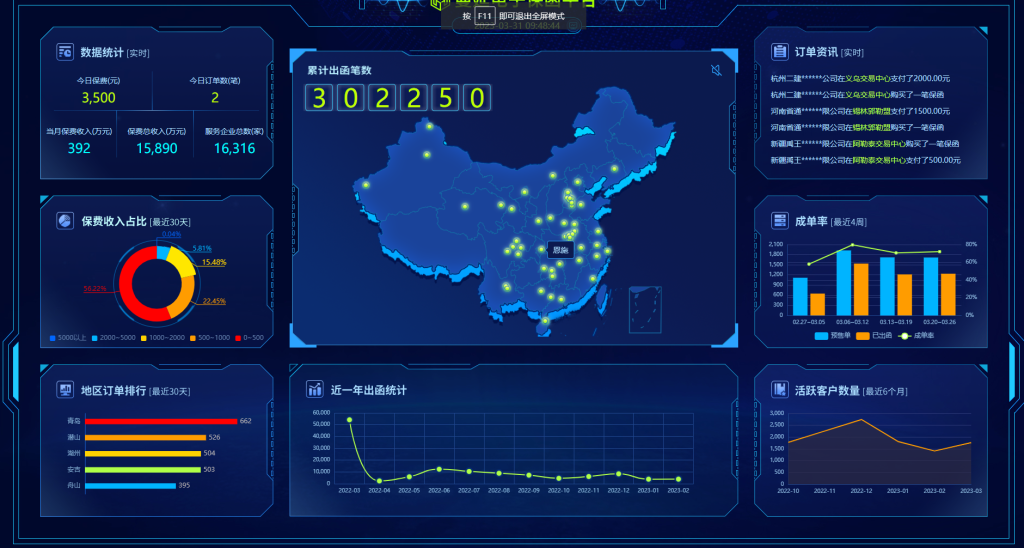
动态效果:(点击下面图片新窗口查看gif效果)
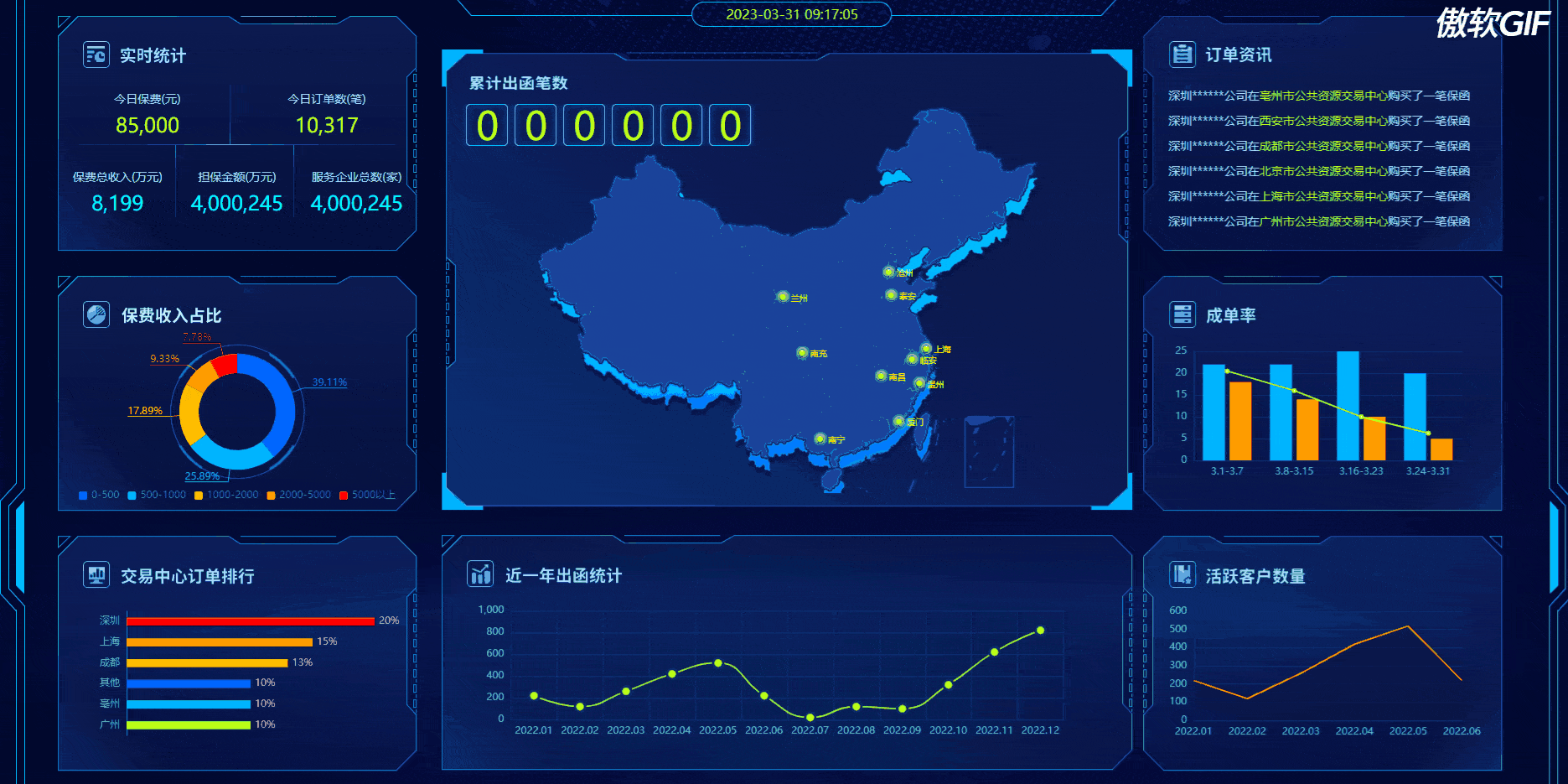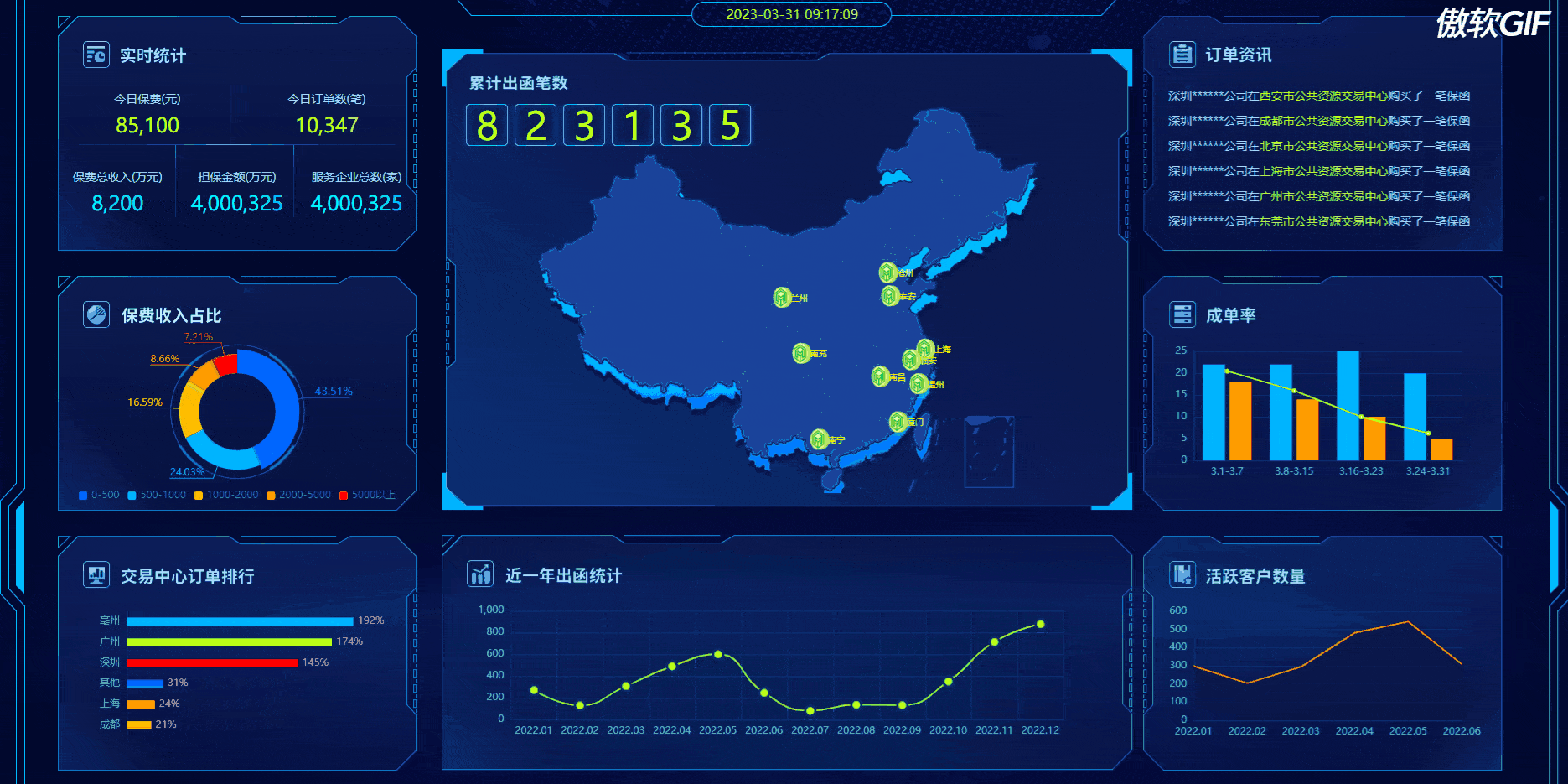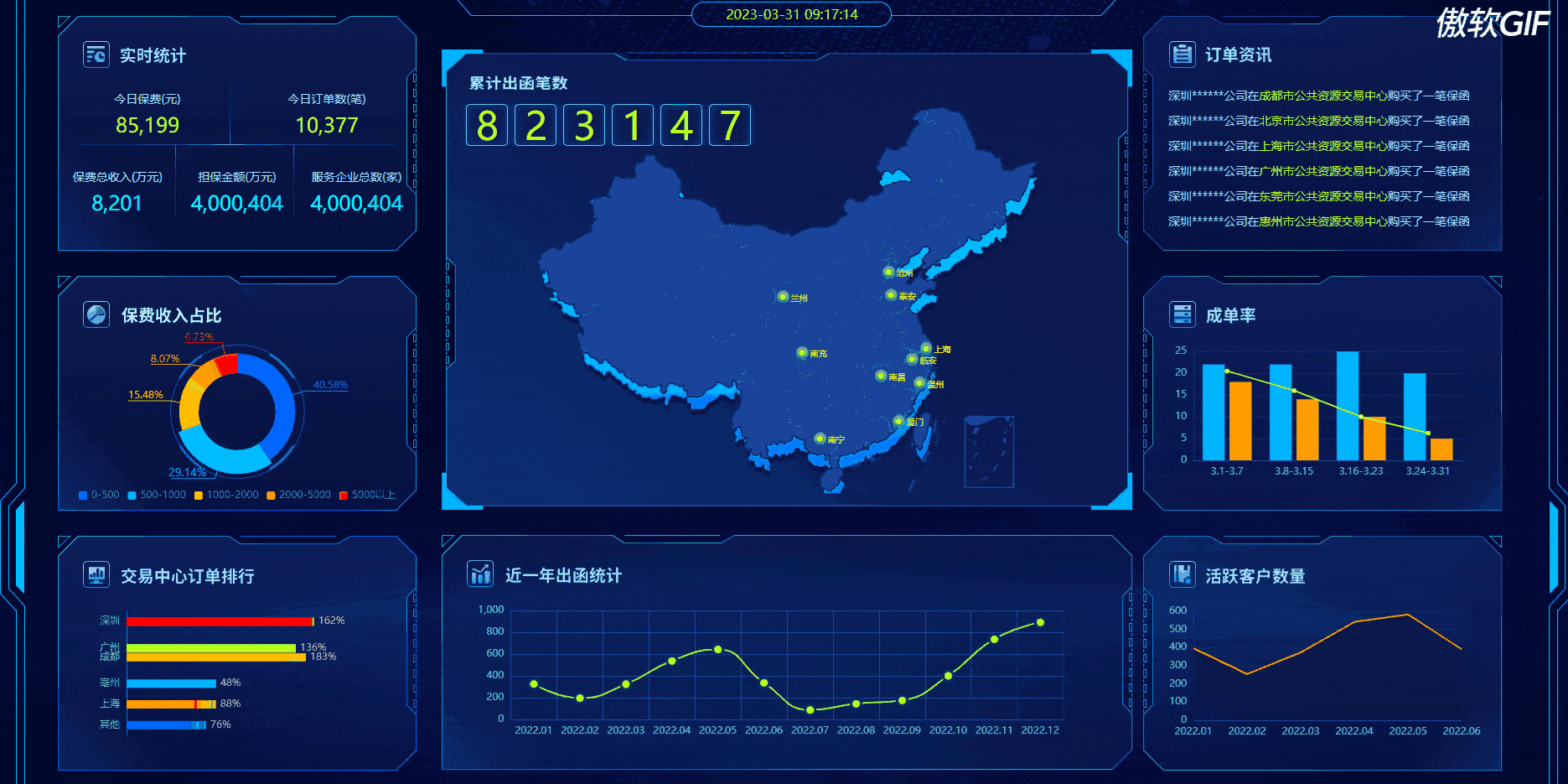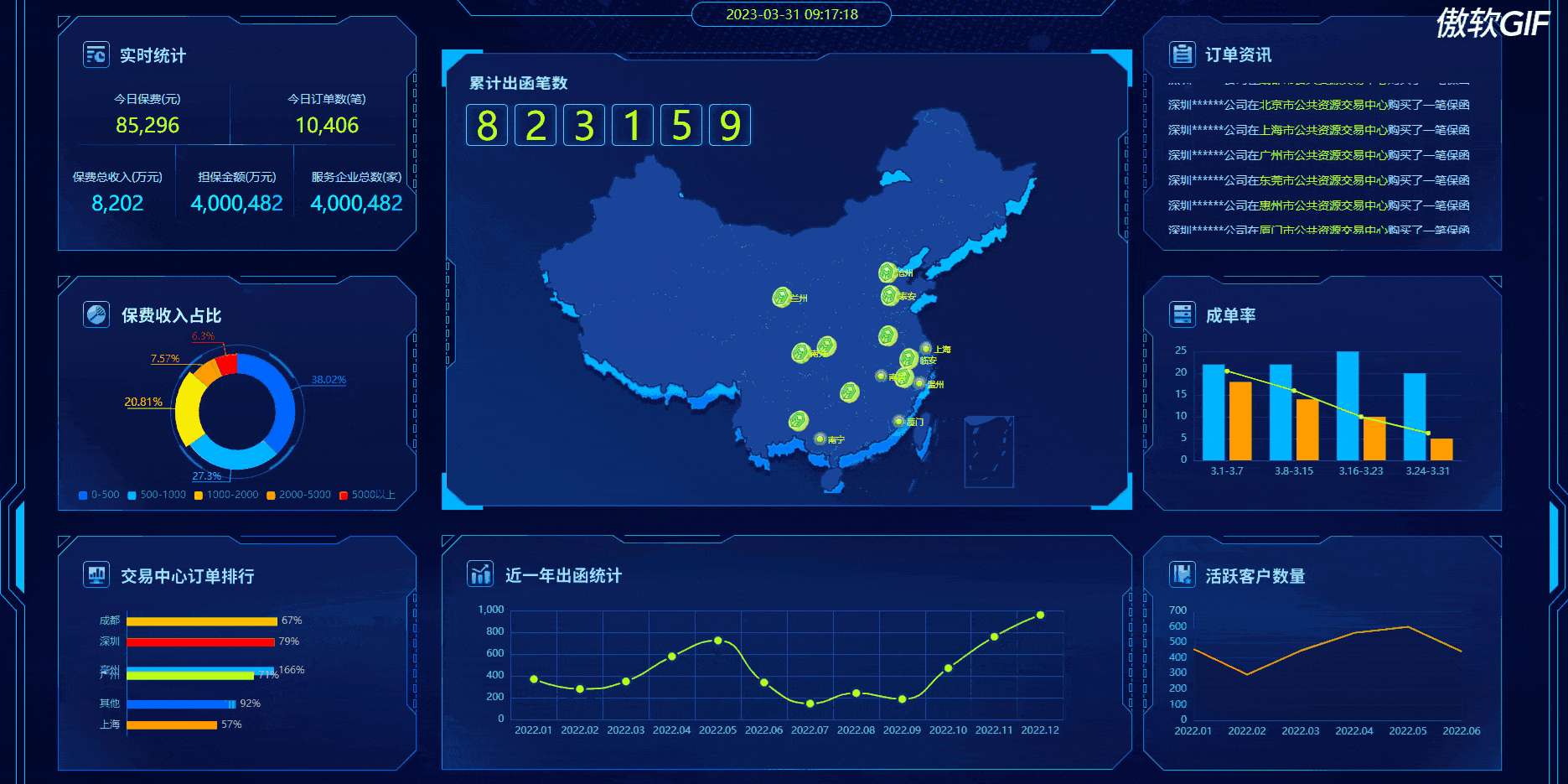
1、实时统计动画效果实现方法:
主要是使用了NPM插件,因为有成熟的,就不必在这个上面浪费时间了
npm i vue-count-to
继续阅读import numpy as np
# 基础款:从列表转数组
data = [1, 2, 3, 4, 5]
arr = np.array(data)
# 懒人专用:自动生成序列
seq1 = np.arange(10) # 0到9
seq2 = np.arange(0, 10, 2) # 0,2,4,6,8
# 做图用的等分点
points = np.linspace(0, 1, 5) # [0, 0.25, 0.5, 0.75, 1]
# 初始化用
zeros = np.zeros((3, 3)) # 3x3零矩阵
ones = np.ones((2, 4)) # 2x4一矩阵
random = np.random.rand(3, 3) # 随机矩阵在公司搞了一阵子Python这玩意儿用起来是爽,但坑也不少。以下分六个类别来介绍,都是血泪教训,今天给大家分享一下。
# 坑:Python 2和Python 3不兼容
# print "hello" # Python 2能跑,Python 3报错
print("hello") # 都得这样写
# 解决方案:
# 无脑用Python 最新版本,别用老的
# 用anaconda管理环境,省心接下来我用Python来训练一个能识别各种花的AI示例,整个过程就像教小朋友认水果一样直观,最后让你理解什么是机器学习。
安装以下Python库:
pip install numpy pandas matplotlib scikit-learn继续分享,不用那些高大上的黑话,就用大白话一步步用Python实现一个最简单的神经网络。
假设有一个超级简单的规则:
0.5。1.0。对我们来说,这太简单了。但对电脑来说,它一开始就是个“婴儿”,啥也不懂。我们需要用“数据”来训练它,让它自己找到 输入 * 2 = 输出 这个规律。
这个“找规律”的过程,就是神经网络的学习过程。
继续阅读最近公司训练AI大模型,我也学习了一下ai知识,今天分享一个用Python写了一个能识别图片里文字的AI!不用任何现成的大模型,就靠最基础的代码。
简单的说就是你画了一个简单的数字“8”,这个AI就能认出它是8!虽然它现在只能认0-9这10个数字,但这就是真正AI识别的原理。
继续阅读
在使用Python实现之前,我们先理解AI的运作模式,假如你面前有一个非常聪明,但完全不识字的“外星大脑”(AI)。它的记忆力超强,算得飞快,但它一开始完全不懂“苹果”、“爱”、“运行”这些词是什么意思。你的任务就是教会它理解人类说的话。
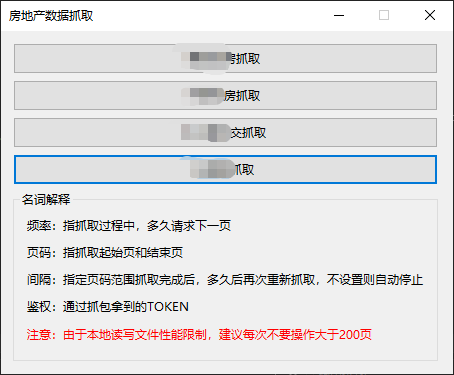
接上个文章,在工作中,给客户完成了定制化房地产数据抓取采集工具,工具使用C#开发,最后打包成自带环境的客户端,又完成了公司派发的一个任务,现在分享一下该工具实现了哪些功能
1、启动界面功能区分,针对不同的抓取内容做定制化窗体开发。
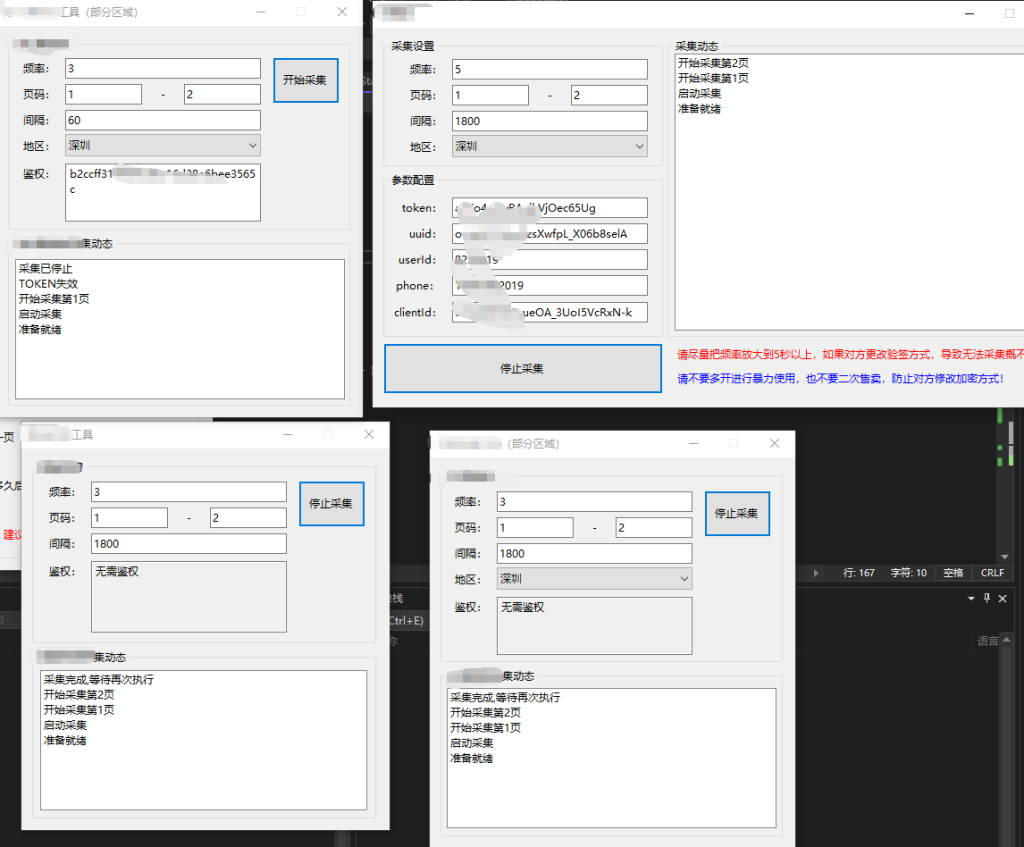
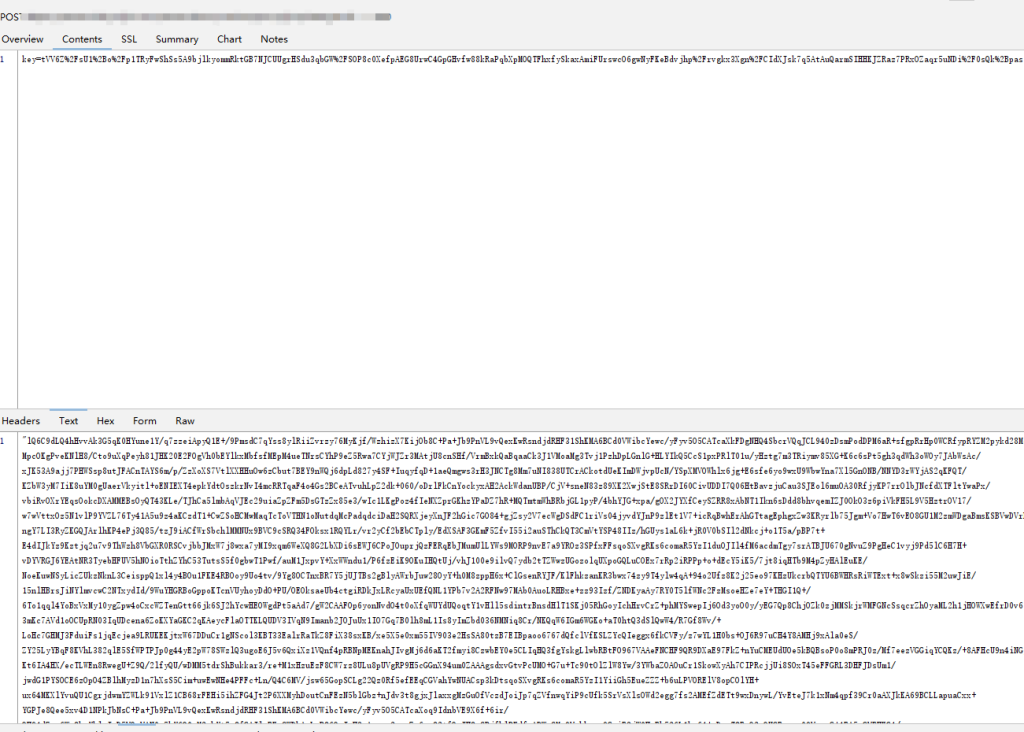
最近博主在工作中做一个APP抓包采集时,发现一个APP的参数和返回都有加密,请求头还做了签名验证,一开始看到这种深度加密的,我是拒绝的,因为这种看到就头疼,很难弄,如图:
隔了2周,客户又找我,让我试试它的小程序,一看小程序也是上面这种方式,刚好那几天闲着没事,一开始我的目标是【先解决返回值解密问题】;
继续阅读以前讲过,单页网站实现SEO的各种办法,目前最优解是nuxtjs,但是这种办法不利于现有项目,现有项目想快速实现百度抓取SEO,最快的就是使用中间件在服务器预渲染。
最近在解决一个老项目实现爬虫SEO过程中,使用了nodejs Prerender 中间件,效果还可以,适用于小型项目,杜绝了代码修改,配置一下服务即可
server {
listen 80;
server_name your_domain.com;
root /your/current/directory;
# 强制所有图片/CSS/JS从当前目录加载
location ~* \.(jpg|png|css|js)$ {
root /your/current/directory;
expires 7d;
access_log off;
}
location / {
# 识别爬虫UA并转发代理
if ($http_user_agent ~* (googlebot|bingbot|baiduspider|twitterbot)) {
proxy_pass http://proxy-service:port;
break;
}
# 正常用户访问本地资源
try_files $uri $uri/ /index.html;
}
}
nodejs Prerender 可以自己在服务器安装一个,安装好后把 http://proxy-service:port 地址换成 本地的 http://127.0.0.1:3000 就可以了
如果嫌麻烦,也可以用我的,不保证服务的稳定性,所以大家还是自己在服务器本地搞个。
http://spa.bbdaxia.com (已停止,流量太大,小资本玩家消耗不起)调用方法就是上面的配置,把地址换成我的服务,不保证稳定性 ,可以用来看一下效果
效果示例:
https://www.bbdaxia.com/shenpiDemo/#/ 这是个单页面应用
下面使用我的服务直接访问 http://spa.bbdaxia.com/https://www.bbdaxia.com/shenpiDemo/#/
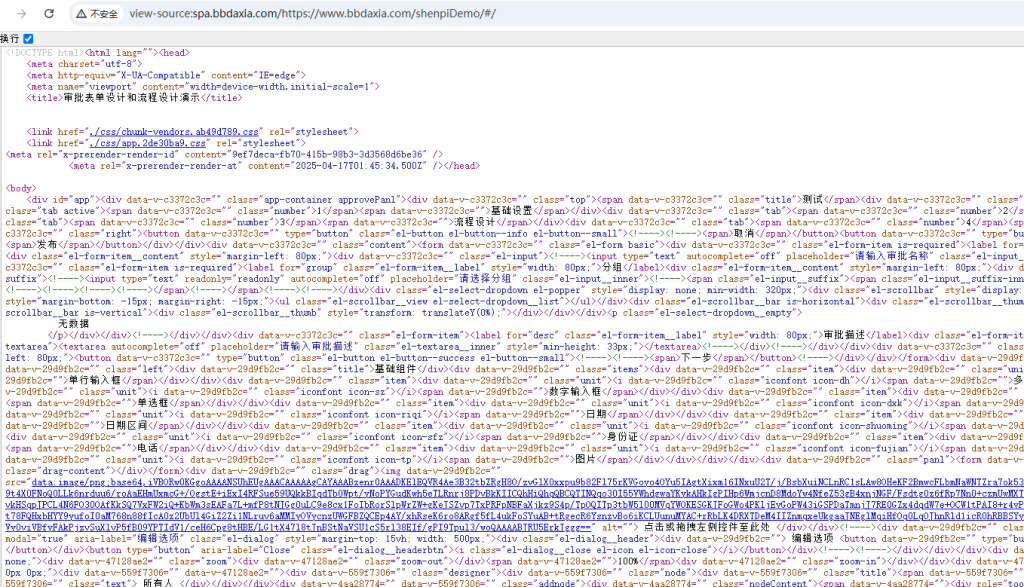
你看可以正常拿到前端运行后的内容,也就是说爬虫来抓也可以了。